
1 Introduction
Scientists and journalists have challenges determining proper citations in the ever increasing sea of information. More fundamentally, when and where a citation is needed—sometimes called citation worthiness—is a crucial first step to solve this challenge. In the general media, some problematic stories have shown that claims need citations to make them verifiable—e.g., the debunked A Rape on Campus article in the Rolling Stone magazine (Wikipedia contributors 2018). Analyses of Wikipedia have revealed that lack of citations correlates with an article’s immaturity (Jack et al. 2014; Chen and Roth 2012). In science, the lack of citations leaves readers wondering how results were built upon previous work (Aksnes and Rip 2009). Also, it precludes researchers from getting appropriate credit, important during hiring and promotion (Gazni and Ghaseminik 2016). The sentences surrounding a citation provide rich information for common semantic analyses, such as information retrieval (Nakov et al. 2004). There should be methods and tools to help scientists cite; in this work, we want to understand where citations should be situated in a paper with the goal of automatically suggesting them.
Relatively much less work has been done on detecting where a citation should be. He et al. (2011) were the first to introduce the task of identifying candidate location where citations are needed in the context of scientific articles. Jack et al. (2014) studied how to detect citation needs in Wikipedia. Peng et al. (2016) used the learning-to-rank framework to solve citation recommendation in news articles. These are very diverse domains, and therefore it is difficult to generalize results. We contend that a large standard dataset of citation location with open code and services would significantly improve the systematic study of the problem. Thus, the task of citation worthiness detection is relatively new and needs further exploration.
The attention mechanism is a relatively recent development in neural networks motivated by human visual attention. Humans get more information from the region they pay attention to, and perceive less from other regions. An attention mechanism in neural networks was first introduced in computer vision (Sun and Fisher 2003), and later applied to NLP for machine translation (Bahdanau et al. 2014). Attention has quickly become adopted in other sub-domains. Luong et al. (2015) examined several attention scoring functions for machine translation. Li et al. (2016) used attention mechanisms to improve results in a question-answering task. Zhou et al. (2016) made use of an attention-based LSTM network to do relational classification. Lin et al. (2017) used attention to improve sentence embedding. Recently, Vaswani et al. (2017) built an architecture called transformer that promises to replace recurrent neural networks (RNNs) altogether by only using attention mechanisms. These results show the advantage of attention for NLP tasks and thus its potential benefit for citation worthiness.
In this study, we formulate the detection of sentences that need citations as a classification task that can be effectively solved with a deep learning architecture that relies on an attention mechanism. Our contributions are the following:
- A deep learning architecture based on bidirectional LSTM with attention and contextual information for citation worthiness
- A new large scale dataset for the citation worthiness task that is 300 times bigger that the next current alternative
- A set of classic interpretable models that provide insights into the language used for making citations
- An examination of common citation mistakes—from unintentional omissions to poten- tially problematic mis-citations
- An evaluation of transfer learning between our proposed dataset and the ACL-ARC dataset
- The code to produce the dataset and results, a web-based tool for the community to evaluate our predictions, and the pre-processed dataset.
2 Data sources and data pre‑processing
2.1 PMOA-CITE
In this paper, We constructed a new dataset called PMOA-CITE based on PubMed central open access subset.
PubMed Central Open Access Subset (PMOAS) is a full-text collection of scientific literature in bio-medical and life sciences. PMOAS is created by the US’s National Institutes of Health. We obtain a snapshot of PMOAS on August, 2019. The dataset consists of more than 2 million full-text journal articles organized in well-structured XML files by the National Information Standards Organization (ANSI/NISO 2013).
We prepare the PMOA-CITE in the following steps:
Sentence segmentation and outlier removal. Text in a PMOAS XML file is marked by a paragraph tag, but there might be other XML tags inside paragraph tags. Therefore, we needed to get all the text of a paragraph from XML tags recursively and break paragraphs into sentences. We used spaCy Python package to do the sentence splitting (
Honnibal and Montani 2017). However, there are some outliers in the sentences (e.g., long gene sequences with more then 10 thousand characters that are treated as one sentence). Base on the distribution of sentence length (see Fig. 3), we remove the sentences that are outliers either in character or word length. We winsorize 5% and 95% quantiles. For character-wise length, this amounts to 19 characters for 5% quantile and 275 characters for 95% quantile. For word-wise length, it is 3 words and 42 words, respectively.Hierarchical tree-like structure. By using section and paragraph tagging information in the XML file and the sentences we extracted in previous step, we construct a hierarchical tree-like structure of the articles. In this structure, sentences are contained within paragraphs, which in turn are contained within sections. For each section, we extract the section-type attribute from the XML file which indicates which kind of section is (from a pre-defined set). For those sections without a section-type, we use the section title instead.
Citation hints removal. The citing sentence usually has some explicit hints which discloses a citation. This provides too much information for the model training and it does not faithfully represents a real-world application scenario. Thus, we removed all the citation hints by regular expression (see Table 1).
| Regular expression | Description | Example |
|---|---|---|
(?<!^)([\[\(])[\s]* ([\d][\s\,\-\–\;\-]*)* [\d][\s]*[\]\)] |
numbers contained in parentheses and square rackets | “[1, 2]”, “[ 1- 2]”, “(1-3)”, “(1,2,3)”, “[1-3, 5]”, “[8],[9],[12]”, “( 1-2; 4-6; 8 )” |
[\(\[]\s*([^\(\)\[\]]* (((16|17|18|19|20) \d{2}(?!\d))| (et[\. \s\\xa0]*al\.)) [^\(\)]*)?[\)\]] |
text within parentheses | “(Kim and li, 2008)”, “(Heijman , 2013b)”, “(Tárraga , 2006; Capella-Gutiérrez , 2009)”, “(Kobayashi et al., 2005)”, “(Richart and Barron, 1969; Campion et al, 1986)”, “(Nasiell et al, 1983, 1986)” |
et[\. \s\\xa0]+al[\.\s\(\[]* ((16|17|18|19|20)\d {2})*[)\] \s]*(?=\D) |
remove et al. and the following years | “et al.”, “et al. 2008”, “et al. (2008)” |
- Noise removal. We apply the following cleanup steps: trim white spaces at beginning and end of a sentence, remove the numbers or punctuations at the beginning of a sentence, and remove numbers at the end of a sentence.
After the processing, we get a dataset (PMOA-CITE) with approximately 309 million sentences. However, due to the computational cost and in order to make all of our analysis manageable, we randomly sample articles whose sentences produce close to one million sentences. We further split the one million sentences, 60% for training, 20% for validating, and 20% for testing.
3 Text Representation
Some of our models use different text representations predicting citation worthiness.
3.1 Bag of words (BoW) representation
We follow the standard definition of term-frequency inverse term-frequency (tf-idf) to construct our bag of words (BoW) representation (Manning et al. 2008). Our BoW representation for a sentence S which consists of n words will therefore be the vector of all tf-idf values in document D_{i}. \text{BoW}(S)=[\text{tf-idf}_{w_{1},D_{i}},...,\text{tf-idf}_{w_{n},D_{i}}] \tag{1}
3.2 Topic modeling based (TM) representation
Topic modeling is a machine learning technique whose goal is to represent a document as a mixture of a small number of “topics”. This reduces the dimensionality needed to represent a document compared to bag-of-words. There are several topic models available including Latent Semantic Analysis (LSA) and Non-negative Matrix Factorization (NMF). In this paper, we use Latent Dirichlet Allocation (LDA), which is one of the most popular and well-motivated approaches.
3.3 Distributed word representation
While topic models can extract statistical structure across documents, they do a relatively poor job at extracting information within documents. In particular, topic models are not meant to find contextual relationships between words. Word embedding methods, in contrast, are based on the distributional hypothesis which states that words that occur in the same context are likely to have similar meaning (Harris, 1954). The famous statement “you shall know a word by the company it keeps” by Firth (1957) is a concise guideline for word embedding: a word could be represented by means of the words surrounding it. In word embedding, words are represented as fixed-length vectors that attempt to approximate their semantic meaning within a document.
There are several distributed word representation methods but one of the most successful and well-known is GloVe by Pennington et al. (2014). We use GloVe word vectors with 300 dimensions, pre-trained on 6 billion tokens.
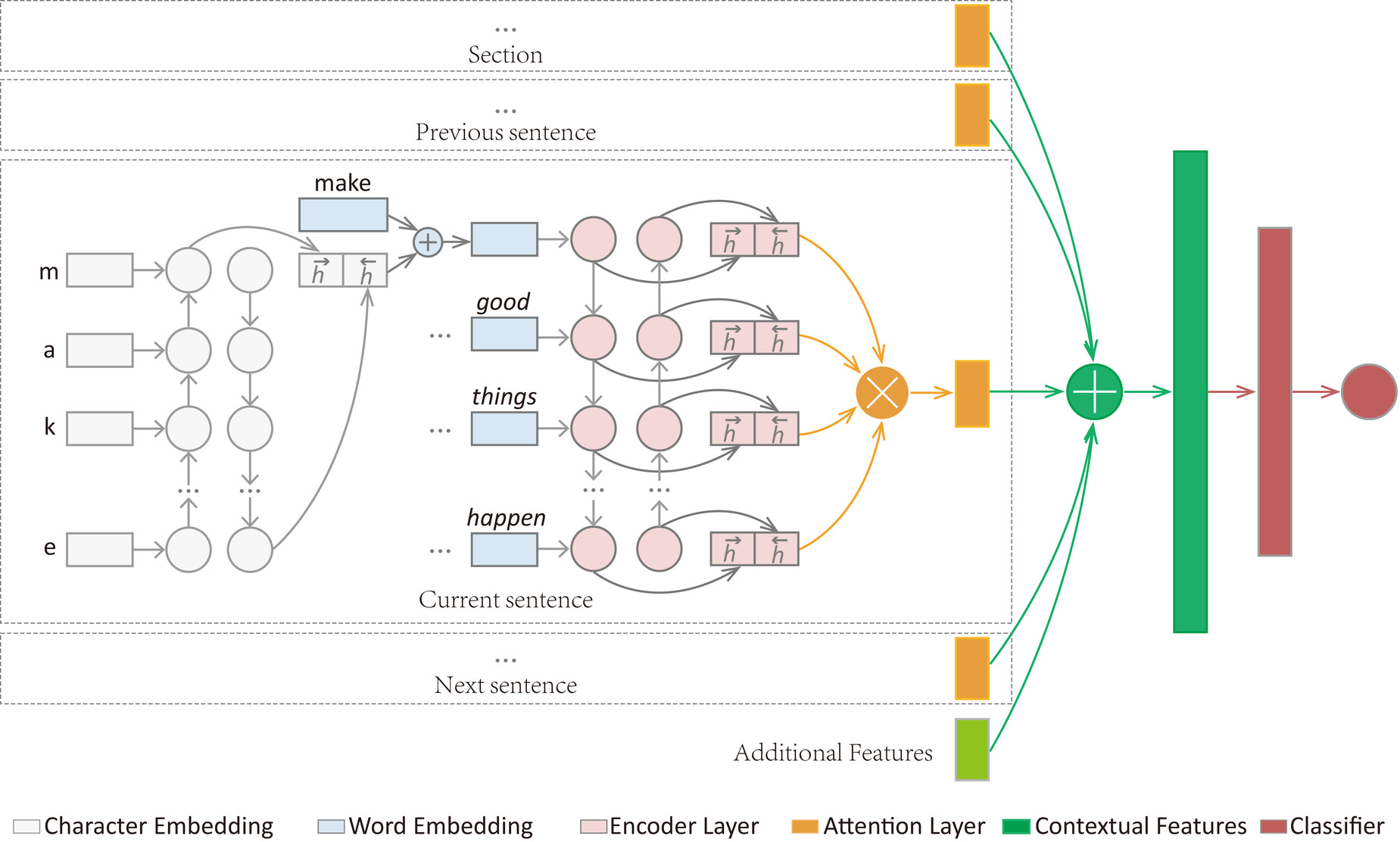
4 An attention‑based BiLSTM architecture for citation worthiness
In this section, we describe our new architecture for improving upon the performance of classic statistical learning models presented above. Importantly, these models might neglect some of the interpretability but might pay large performance dividends. Generally, they do not need hand-crafted features. At a high level, the architecture we propose has the following layers (also Figure 1):
- Character embedding layer: encode every character in a word using a bidirectional LSTM, and get a vector representation of a word.
- Word embedding layer: convert the tokens into vectors by using pre-trained vectors.
- Encoder layer: use a bidirectional LSTM which captures both the forward and backward information flow.
- Attention layer: make use of an attention mechanism to interpolate the hidden states of the encoder (explained below)
- Contextual Features layer: obtain the contextual features by combining features of sec- tion, previous sentence, current sentence, and next sentence.
- Classifier layer: use a multilayer perceptron to produce the final prediction of citation worthiness.
5 Results
Please read the paper for details.
6 Discussion
In this work, we developed methods and a large dataset for improving the detection of citation worthiness. Citation worthiness is an important first step for constructing robust and well-structured arguments in science. It is crucial for determining where sources of ideas should mentioned within a manuscript. Previous research has shown promising results but thanks to our new large dataset and modern deep learning architecture, we were able to achieve significantly good performance. We additionally proposed several techniques to interpret what makes scientists use citations. We uncovered potential issues in citation data and behavior: XML documents not properly tagged, citations in the wrong form, and, even worse, scientists failing to cite when they should have. We make our code and a web-based tool available for the scientific community. Our results and new datasets should contribute to the larger need to complement scientific writing with automated techniques. Taken together, our results suggest that deep learning with modern attention-based mechanisms can be effectively used for citation worthiness. We now describe contributions in the context of other work and potential limitations of our approach.
As an enhancement to the ACL-ARC dataset, we proposed the PMOA-CITE dataset in the hope of facilitating research on the citation worthiness task. This extends the datasets available to the field of bio-medical science. Our improvements are 1) a two orders of mag- nitude increase in data size, 2) a well-structured XML file that is less noisy, and 3) contextual information. This dataset could be potentially used in other citation context-related research, such as text summarization (Chen and Zhuge 2019), or citation recommendation (Huang et al. 2015). Therefore, our contribution goes beyond the application of citation worthiness.
Based on the experiments on PMOA-CITE dataset, the use of contextual features consistently improved the performance. This improvement was independent of the algorithm and text representation used (Tables 4 and 7) . A similar results was reported in He et al. (2010) and Jochim and Schütze (2012)). This suggests that contextual information was key for citation worthiness and other related tasks.
In order to facilitate future research, we made our datasets and models available to the public. The links of the dataset and the code parsing XML files are available at https://github.com/sciosci/cite-worthiness . We also built a web-based tool (see Fig. 8) at http://cite-worthiness.scienceofscience.org. This tool might help inform journalist, policy makers, the public to better understand the principles of proper source citation and credit assignment.
Citation
@article{zeng2020,
author = {Zeng, Tong and E Acuna, Daniel},
title = {Modeling Citation Worthiness by Using Attention‑based
Bidirectional Long Short‑term Memory Networks and Interpretable
Models},
journal = {Scientometrics},
volume = {124},
number = {1},
pages = {399-428},
date = {2020-07},
url = {https://link.springer.com/article/10.1007/s11192-020-03421-9},
doi = {10.1007/s11192-020-03421-9},
issn = {0138-9130},
langid = {en},
abstract = {Scientist learn early on how to cite scientific sources to
support their claims. Sometimes, however, scientists have challenges
determining where a citation should be situated—or, even worse, fail
to cite a source altogether. Automatically detecting sentences that
need a citation (i.e., citation worthiness) could solve both of
these issues, leading to more robust and well-constructed scientific
arguments. Previous researchers have applied machine learning to
this task but have used small datasets and models that do not take
advantage of recent algorithmic developments such as attention
mechanisms in deep learning. We hypothesize that we can develop
significantly accurate deep learning architectures that learn from
large supervised datasets constructed from open access publications.
In this work, we propose a bidirectional long short-term memory
network with attention mechanism and contextual information to
detect sentences that need citations. We also produce a new, large
dataset (PMOA-CITE) based on PubMed Open Access Subset, which is
orders of magnitude larger than previous datasets. Our experiments
show that our architecture achieves state of the art performance on
the standard ACL-ARC dataset ( F1 = 0.507) and exhibits high
performance ( F1 = 0.856) on the new PMOA-CITE. Moreover, we show
that it can transfer learning across these datasets. We further use
interpretable models to illuminate how specific language is used to
promote and inhibit citations. We discover that sections and
surrounding sentences are crucial for our improved predictions. We
further examined purported mispredictions of the model, and
uncovered systematic human mistakes in citation behavior and source
data. This opens the door for our model to check documents during
pre-submission and pre-archival procedures. We discuss limitations
of our work and make this new dataset, the code, and a web-based
tool available to the community.}
}